Introduction to Large Language Model (LLM)#
How do large language models work?#
Let’s have a look at how large language models work, with a focus on OpenAI GPT (Generative Pre-trained Transformer) models.
Tokenizer, text to numbers: Large Language Models receive a text as input and generate a text as output. However, being statistical models, they work much better with numbers than text sequences. That’s why every input to the model is processed by a tokenizer, before being used by the core model. A token is a chunk of text – consisting of a variable number of characters, so the tokenizer’s main task is splitting the input into an array of tokens. Then, each token is mapped with a token index, which is the integer encoding of the original text chunk.
Predicting output tokens: Given n tokens as input (with max n varying from one model to another), the model is able to predict one token as output. This token is then incorporated into the input of the next iteration, in an expanding window pattern, enabling a better user experience of getting one (or multiple) sentence as an answer. This explains why, if you ever played with ChatGPT, you might have noticed that sometimes it looks like it stops in the middle of a sentence.
Selection process, probability distribution: The output token is chosen by the model according to its probability of occurring after the current text sequence. This is because the model predicts a probability distribution over all possible ‘next tokens’, calculated based on its training. However, not always the token with the highest probability is chosen from the resulting distribution. A degree of randomness is added to this choice, in a way that the model acts in a non-deterministic fashion - we do not get the exact same output for the same input. This degree of randomness is added to simulate the process of creative thinking and it can be tuned using a model parameter called temperature.
Learn more about LLM concepts here:
Improving LLM results#
There are several approaches a business can use to get the results they need from an LLM. You can select different types of models with different degrees of training when deploying an LLM in production, with different levels of complexity, cost, and quality. Here are some different approaches:
Prompt engineering with context. The idea is to provide enough context when you prompt to ensure you get the responses you need.
Retrieval Augmented Generation, RAG. Your data might exist in a database or web endpoint for example, to ensure this data, or a subset of it, is included at the time of prompting, you can fetch the relevant data and make that part of the user’s prompt.
Fine-tuned model. Here, you trained the model further on your own data which leads to the model being more exact and responsive to your needs but might be costly.
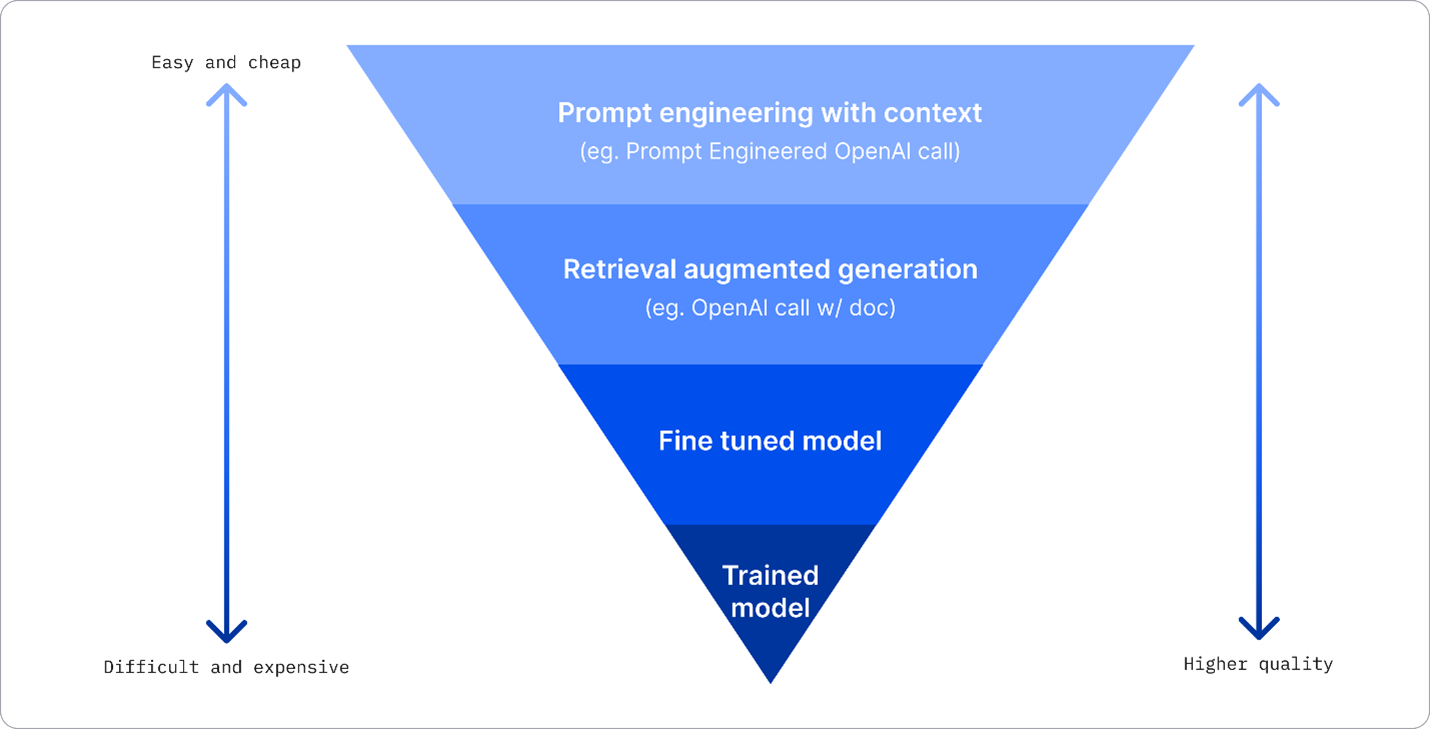
Fig. 5 Four Ways that Enterprises Deploy LLMs | Fiddler AI Blog#