Analyzing Text about Artificial Intelligence#
In this notebook, we experiment with a wikipedia article on artificial intelligence. You can see that, this article contains a lot of terms, this making the analysis more problematic. We need to come up with another way to clean up the data after doing keyword extraction, to get rid of some frequent, but not meaningful word combinations.
Goal#
In this lesson, we will be discussing concepts related to Data Science by doing some text mining. We will start with a text about artificial intelligence, extract keywords from it, and then try to visualize the result.
url = "https://en.wikipedia.org/wiki/Artificial_intelligence"
Step 1: Getting the Data#
First step in every data science process is getting the data. We will use requests library to do that:
import requests
text = requests.get(url).content.decode("utf-8")
text[:1000]
'<!DOCTYPE html>\n<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu-pinned-disabled vector-feature-limited-width-clientpref-1 vector-feature-limited-width-content-enabled vector-feature-custom-font-size-clientpref-1 vector-feature-appearance-enabled vector-feature-appearance-pinned-clientpref-1 vector-feature-night-mode-enabled skin-theme-clientpref-day vector-toc-available" lang="en" dir="ltr">\n<head>\n<meta charset="UTF-8">\n<title>Artificial intelligence - Wikipedia</title>\n<script>(function(){var className="client-js vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu-pinned-disabled vector-f'
Step 2: Transforming the Data#
The next step is to convert the data into the form suitable for processing. In our case, we have downloaded HTML source code from the page, and we need to convert it into plain text.
There are many ways this can be done. We will use the simplest build-in HTMLParser object from Python. We need to subclass the HTMLParser class and define the code that will collect all text inside HTML tags, except <script> and <style> tags.
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
script = False
res = ""
def handle_starttag(self, tag, attrs):
if tag.lower() in ["script", "style"]:
self.script = True
def handle_endtag(self, tag):
if tag.lower() in ["script", "style"]:
self.script = False
def handle_data(self, data):
if str.strip(data) == "" or self.script:
return
self.res += " " + data.replace("[ edit ]", "")
parser = MyHTMLParser()
parser.feed(text)
text = parser.res
text[:1000]
' Artificial intelligence - Wikipedia Jump to content Main menu Main menu move to sidebar hide \n\t\tNavigation\n\t Main page Contents Current events Random article About Wikipedia Contact us Donate \n\t\tContribute\n\t Help Learn to edit Community portal Recent changes Upload file Search Search Appearance Create account Log in Personal tools Create account Log in \n\t\tPages for logged out editors learn more Contributions Talk Contents move to sidebar hide (Top) 1 Goals Toggle Goals subsection 1.1 Reasoning and problem-solving 1.2 Knowledge representation 1.3 Planning and decision-making 1.4 Learning 1.5 Natural language processing 1.6 Perception 1.7 Social intelligence 1.8 General intelligence 2 Techniques Toggle Techniques subsection 2.1 Search and optimization 2.1.1 State space search 2.1.2 Local search 2.2 Logic 2.3 Probabilistic methods for uncertain reasoning 2.4 Classifiers and statistical learning methods 2.5 Artificial neural networks 2.6 Deep learning 2.7 GPT 2.8 Specialized hardware and'
Step 3: Getting Insights#
The most important step is to turn our data into some for from which we can draw insights. In our case, we want to extract keywords from the text, and see which keywords are more meaningful.
We will use Python library called RAKE for keyword extraction. First, let’s install this library in case it is not present:
!poetry add nlp_rake
The following packages are already present in the pyproject.toml and will be skipped:
- nlp_rake
If you want to update it to the latest compatible version, you can use `poetry update package`.
If you prefer to upgrade it to the latest available version, you can use `poetry add package@latest`.
Nothing to add.
The main functionality is available from Rake object, which we can customize using some parameters. In our case, we will set the minimum length of a keyword to 5 characters, minimum frequency of a keyword in the document to 3, and maximum number of words in a keyword - to 2. Feel free to play around with other values and observe the result.
import nlp_rake
extractor = nlp_rake.Rake(max_words=2, min_freq=3, min_chars=5)
res = extractor.apply(text)
res
[('autonomous vehicles', 4.0),
('21st century', 4.0),
('speech recognition', 4.0),
('gradient descent', 4.0),
('neural networks', 4.0),
('data centers', 4.0),
('bad actors', 4.0),
('algorithmic bias', 4.0),
('existential risk', 4.0),
('elon musk', 4.0),
('scientific american', 4.0),
('issn 0261-3077', 4.0),
('ars technica', 4.0),
('fox news', 4.0),
('2nd ed', 4.0),
('bbc news', 4.0),
('^ wong', 3.9957805907173),
('ai winter', 3.99290780141844),
('regulate ai', 3.99290780141844),
('strong ai', 3.99290780141844),
('ai magazine', 3.99290780141844),
('recommendation systems', 3.909090909090909),
('ai systems', 3.901998710509349),
('affective computing', 3.9),
('make decisions', 3.888888888888889),
('artificial intelligence', 3.884892086330935),
('intelligence explosion', 3.884892086330935),
('modern ai', 3.86790780141844),
('deep learning', 3.8),
('training data', 3.8),
('united states', 3.8),
('turing test', 3.7333333333333334),
('commonsense knowledge', 3.730769230769231),
('york times', 3.7272727272727275),
('ai research', 3.7170457324529225),
('mit press', 3.7142857142857144),
('computing machinery', 3.7),
('ai researchers', 3.6987901543596164),
('general intelligence', 3.6848920863309353),
('joint statement', 3.666666666666667),
('soft computing', 3.65),
('racist decisions', 3.638888888888889),
('default reasoning', 3.625),
('^ christian', 3.6068917018284106),
('full employment', 3.6),
('early 2020s', 3.583333333333333),
('specific problems', 3.571428571428571),
('computer vision', 3.560846560846561),
('image classification', 3.541666666666667),
('local search', 3.533333333333333),
('knowledge representation', 3.5307692307692307),
('^ quoted', 3.4957805907173),
('ai applications', 3.49290780141844),
('human rights', 3.4761904761904763),
('ai tools', 3.4544462629569015),
('machine learning', 3.4511627906976745),
('ai programs', 3.4214792299898686),
('computer science', 3.3537037037037036),
('^ domingos', 3.2957805907172997),
('machine ethics', 3.294019933554817),
('^ crevier', 3.2898982377761232),
('^ russell', 3.254283992077844),
('uncertain reasoning', 3.25),
('guardian weekly', 3.25),
('google search', 3.2),
('retrieved 2024-08-07', 3.2),
('intelligence', 1.8848920863309353),
('information', 1.85),
('human', 1.8333333333333333),
('learning', 1.8),
('logic', 1.75),
('turing', 1.7333333333333334),
('knowledge', 1.7307692307692308),
('algorithms', 1.7272727272727273),
('decision', 1.7272727272727273),
('intelligent', 1.7272727272727273),
('system', 1.7272727272727273),
('research', 1.7241379310344827),
('press', 1.7142857142857142),
('researchers', 1.7058823529411764),
('computer', 1.7037037037037037),
('model', 1.6666666666666667),
('google', 1.6666666666666667),
('privacy', 1.6666666666666667),
('experts', 1.6666666666666667),
('approach', 1.6666666666666667),
('machine', 1.6511627906976745),
('science', 1.65),
('ethics', 1.6428571428571428),
('rights', 1.6428571428571428),
('called', 1.6363636363636365),
('person', 1.625),
('reasoning', 1.625),
('uncertain', 1.625),
('models', 1.6153846153846154),
('christian', 1.6111111111111112),
('actions', 1.6),
('problems', 1.5714285714285714),
('language', 1.5714285714285714),
('solutions', 1.5555555555555556),
('network', 1.5555555555555556),
('report', 1.5555555555555556),
('search', 1.5333333333333334),
('methods', 1.5333333333333334),
('theory', 1.5333333333333334),
('software', 1.5),
('funding', 1.5),
('government', 1.5),
('humans', 1.5),
('based', 1.5),
('typically', 1.5),
('input', 1.5),
('computation', 1.5),
('applications', 1.5),
('fusion', 1.5),
('algorithm', 1.5),
('regulation', 1.5),
('issue', 1.5),
('quoted', 1.5),
('tools', 1.4615384615384615),
('analysis', 1.4545454545454546),
('planning', 1.4545454545454546),
('consciousness', 1.4545454545454546),
('problem', 1.4516129032258065),
('optimization', 1.4444444444444444),
('potential', 1.4444444444444444),
('agent', 1.4375),
('things', 1.4285714285714286),
('improve', 1.4285714285714286),
('programs', 1.4285714285714286),
('nodes', 1.4285714285714286),
('white', 1.4285714285714286),
('searle', 1.4285714285714286),
('review', 1.4285714285714286),
('risks', 1.4210526315789473),
('chess', 1.4),
('statements', 1.4),
('measures', 1.4),
('truth', 1.4),
('require', 1.4),
('inputs', 1.4),
('important', 1.4),
('images', 1.4),
('users', 1.4),
('biased', 1.4),
('eventually', 1.4),
('principles', 1.4),
('americans', 1.4),
('similar', 1.4),
('threat', 1.4),
('hinton', 1.4),
('george', 1.4),
('technology', 1.3846153846153846),
('question', 1.375),
('approaches', 1.375),
('stuart', 1.375),
('thinking', 1.375),
('moravec', 1.375),
('minsky', 1.375),
('journal', 1.375),
('solve', 1.3636363636363635),
('misinformation', 1.3636363636363635),
('people', 1.35),
('facts', 1.3333333333333333),
('number', 1.3333333333333333),
('situation', 1.3333333333333333),
('choose', 1.3333333333333333),
('agents', 1.3333333333333333),
('automation', 1.3333333333333333),
('tasks', 1.3333333333333333),
('superintelligence', 1.3333333333333333),
('capable', 1.3333333333333333),
('bostrom', 1.3333333333333333),
('simon', 1.3333333333333333),
('goals', 1.3076923076923077),
('future', 1.3),
('domingos', 1.3),
('schmidhuber', 1.3),
('developed', 1.2941176470588236),
('world', 1.2941176470588236),
('crevier', 1.2941176470588236),
('solution', 1.2857142857142858),
('identify', 1.2857142857142858),
('discovery', 1.2857142857142858),
('fairness', 1.2857142857142858),
('survey', 1.2857142857142858),
('history', 1.2857142857142858),
('mccarthy', 1.2857142857142858),
('anderson', 1.2857142857142858),
('vincent', 1.2857142857142858),
('machines', 1.28),
('robots', 1.2777777777777777),
('process', 1.2727272727272727),
('development', 1.2727272727272727),
('difficult', 1.2727272727272727),
('russell', 1.2585034013605443),
('considered', 1.25),
('healthcare', 1.25),
('fields', 1.25),
('1990s', 1.25),
('probability', 1.25),
('domains', 1.25),
('utility', 1.25),
('making', 1.25),
('rules', 1.25),
('inference', 1.25),
('designed', 1.25),
('classifiers', 1.25),
('neurons', 1.25),
('services', 1.25),
('reported', 1.25),
('microsoft', 1.25),
('content', 1.25),
('gender', 1.25),
('developers', 1.25),
('introduced', 1.25),
('recommendations', 1.25),
('explain', 1.25),
('impossible', 1.25),
('works', 1.25),
('newell', 1.25),
('scruffies', 1.25),
('evolution', 1.25),
('atlantic', 1.25),
('michael', 1.25),
('newquist', 1.25),
('bengio', 1.25),
('guardian', 1.25),
('marvin', 1.25),
('program', 1.2307692307692308),
('chatgpt', 1.2222222222222223),
('learned', 1.2222222222222223),
('robotics', 1.2142857142857142),
('sentience', 1.2),
('perception', 1.2),
('situations', 1.2),
('state', 1.2),
('sensors', 1.2),
('generation', 1.2),
('trained', 1.2),
('output', 1.2),
('reason', 1.2),
('backpropagation', 1.2),
('governance', 1.2),
('narrow', 1.2),
('conference', 1.2),
('economist', 1.2),
('retrieved 26', 1.2),
('retrieved 23', 1.2),
('brooks', 1.2),
('dangers', 1.2),
('areas', 1.1666666666666667),
('understanding', 1.1666666666666667),
('terms', 1.1666666666666667),
('singularity', 1.1666666666666667),
('techniques', 1.1428571428571428),
('outputs', 1.1428571428571428),
('humanity', 1.1428571428571428),
('1960s', 1.1428571428571428),
('companies', 1.125),
('study', 1.125),
('definition', 1.125),
('mccorduck', 1.1176470588235294),
('learn', 1.1111111111111112),
('action', 1.1111111111111112),
('society', 1.1111111111111112),
('dreyfus', 1.1111111111111112),
('computers', 1.0909090909090908),
('nilsson', 1.0666666666666667),
('field', 1.0555555555555556),
('norvig', 1.0425531914893618),
('original', 1.0097087378640777),
('environment', 1.0),
('maximize', 1.0),
('youtube', 1.0),
('amazon', 1.0),
('founded', 1.0),
('universities', 1.0),
('ensure', 1.0),
('reach', 1.0),
('statistics', 1.0),
('economics', 1.0),
('philosophy', 1.0),
('objects', 1.0),
('relations', 1.0),
('breadth', 1.0),
('difficulty', 1.0),
('happen', 1.0),
('outcome', 1.0),
('occur', 1.0),
('performance', 1.0),
('beginning', 1.0),
('kinds', 1.0),
('predict', 1.0),
('types', 1.0),
('required', 1.0),
('meaning', 1.0),
('ability', 1.0),
('result', 1.0),
('order', 1.0),
('survive', 1.0),
('inspired', 1.0),
('proving', 1.0),
('premises', 1.0),
('labelled', 1.0),
('solved', 1.0),
('competitive', 1.0),
('observation', 1.0),
('widely', 1.0),
('1950s', 1.0),
('token', 1.0),
('chatbots', 1.0),
('facebook', 1.0),
('medicine', 1.0),
('suggested', 1.0),
('player', 1.0),
('mathematics', 1.0),
('working', 1.0),
('serve', 1.0),
('thousands', 1.0),
('november 2023', 1.0),
('circumstances', 1.0),
('purpose', 1.0),
('matter', 1.0),
('found', 1.0),
('opposed', 1.0),
('context', 1.0),
('showed', 1.0),
('features', 1.0),
('presented', 1.0),
('cases', 1.0),
('asthma', 1.0),
('china', 1.0),
('easier', 1.0),
('powerful', 1.0),
('trust', 1.0),
('challenges', 1.0),
('congress', 1.0),
('openai', 1.0),
('define', 1.0),
('understand', 1.0),
('darwin', 1.0),
('arthur', 1.0),
('luger', 1.0),
('stubblefield', 1.0),
('poole', 1.0),
('mackworth', 1.0),
('goebel', 1.0),
('1016/j', 1.0),
('proposal', 1.0),
('goertzel', 1.0),
('kahneman', 1.0),
('jordan', 1.0),
('mitchell', 1.0),
('cambria', 1.0),
('james', 1.0),
('venturebeat', 1.0),
('evans', 1.0),
('nature', 1.0),
('bibcode', 1.0),
('gregory', 1.0),
('yorker', 1.0),
('verge', 1.0),
('1126/science', 1.0),
('wired', 1.0),
('david', 1.0),
('martin', 1.0),
('archived', 1.0),
('steven', 1.0),
('daniel', 1.0),
('brian', 1.0),
('samuel', 1.0),
('sainato', 1.0),
('mcgaughey', 1.0),
('zierahn', 1.0),
('forbes', 1.0),
('kurzweil', 1.0),
('peter', 1.0),
('kevin', 1.0),
('strategies', 1.0),
('citeseerx 10', 1.0),
('arxiv', 1.0),
('steve', 1.0)]
We obtained a list terms together with associated degree of importance. As you can see, the most relevant disciplines, such as neural networks, autonomous vehicles, and speech recognition, are present in the list at top positions.
Step 4: Visualizing the Result#
People can interpret the data best in the visual form. Thus it often makes sense to visualize the data in order to draw some insights. We can use matplotlib library in Python to plot simple distribution of the keywords with their relevance:
import matplotlib.pyplot as plt
def plot(pair_list):
k, v = zip(*pair_list)
plt.bar(range(len(k)), v)
plt.xticks(range(len(k)), k, rotation="vertical")
plt.show()
plot(res[:30])
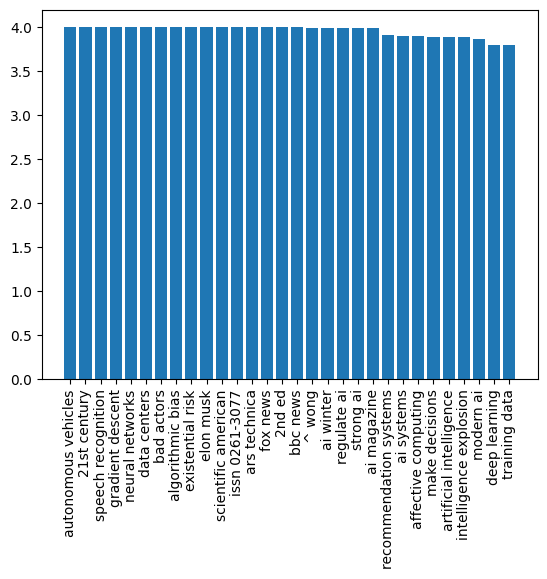
There is, however, even better way to visualize word frequencies - using Word Cloud. We will need to install another library to plot the word cloud from our keyword list.
!poetry add wordcloud
The following packages are already present in the pyproject.toml and will be skipped:
- wordcloud
If you want to update it to the latest compatible version, you can use `poetry update package`.
If you prefer to upgrade it to the latest available version, you can use `poetry add package@latest`.
Nothing to add.
WordCloud object is responsible for taking in either original text, or pre-computed list of words with their frequencies, and returns and image, which can then be displayed using matplotlib:
import matplotlib.pyplot as plt
from wordcloud import WordCloud
wc = WordCloud(background_color="white", width=800, height=600)
plt.figure(figsize=(15, 7))
plt.imshow(wc.generate_from_frequencies({k: v for k, v in res}))
plt.show()
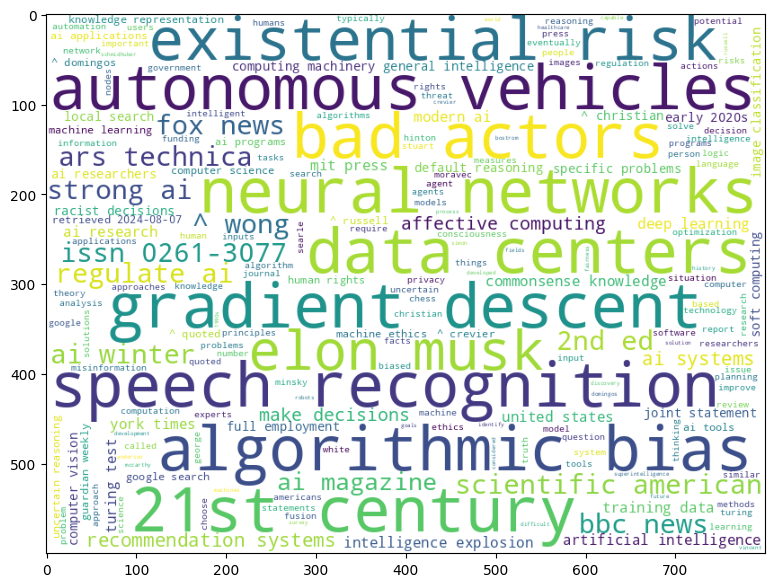
We can also pass in the original text to WordCloud - let’s see if we are able to get similar result:
plt.figure(figsize=(15, 7))
plt.imshow(wc.generate(text))
plt.show()

You can see that word cloud now looks more impressive, but it also contains a lot of noise (eg. unrelated words such as including). Also, we get fewer keywords that consist of two words, such as neural networks or gradient descent. This is because RAKE algorithm does much better job at selecting good keywords from text. This example illustrates the importance of data pre-processing and cleaning, because clear picture at the end will allow us to make better decisions.
In this exercise we have gone through a simple process of extracting some meaning from Wikipedia text, in the form of keywords and word cloud. This example is quite simple, but it demonstrates well all typical steps a data scientist will take when working with data, starting from data acquisition, up to visualization.