Visual Introduction to Pandas#
import pandas as pd
Loading Data#
Dengan menggunakan Pandas, kamu bisa memuat data spreadsheet (tabel) lalu memanipulasinya menggunakan Python. Konsep utama dari Pandas adalah objek DataFrame, yaitu tipe data yang merepresentastikan tabel beserta isinya dan memiliki label pada setiap baris dan kolom.
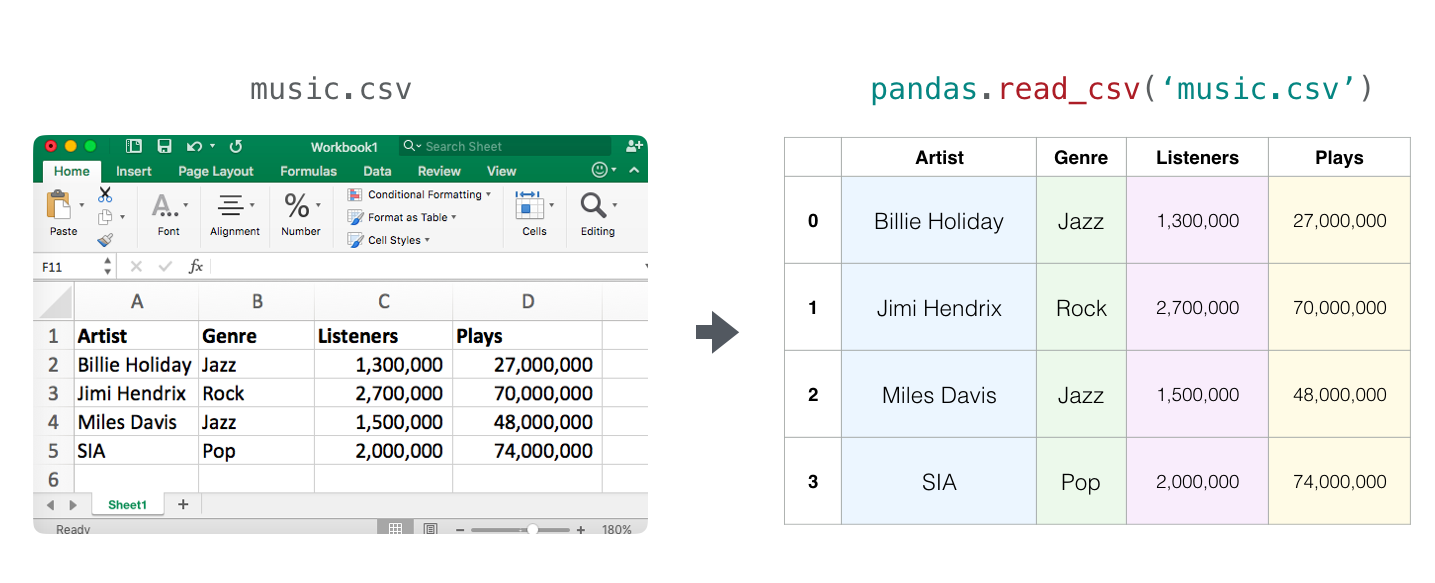
df = pd.read_csv("../../data/music.csv")
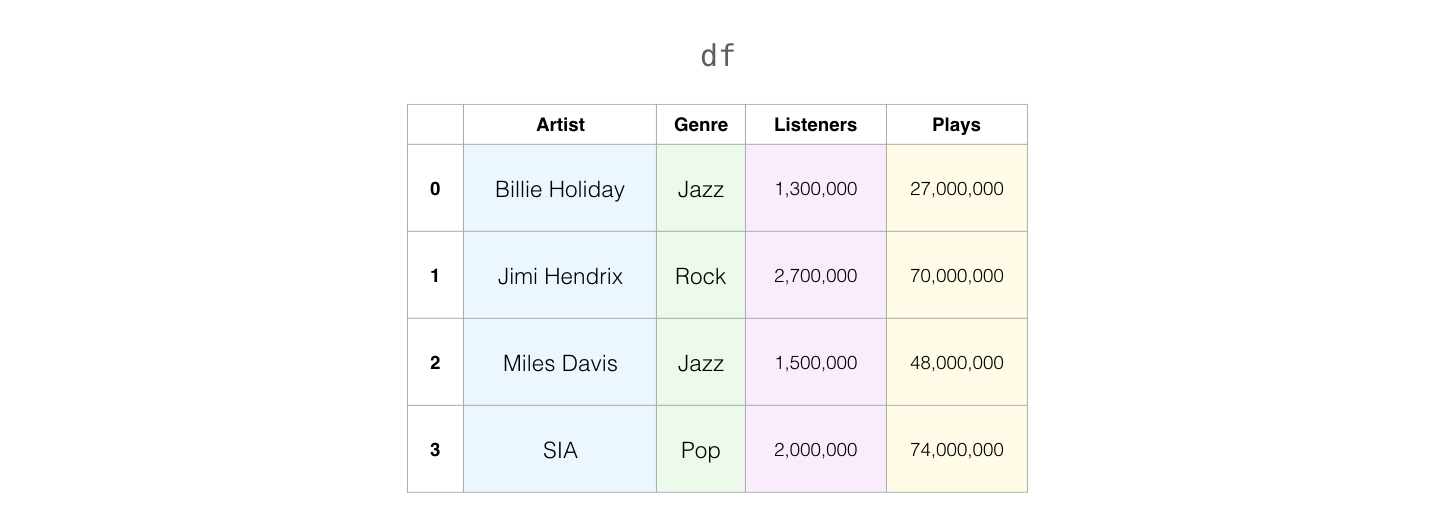
df
| Artist | Genre | Listeners | Plays | |
|---|---|---|---|---|
| 0 | Billie Holiday | Jazz | 1300000 | 27000000 |
| 1 | Jimi Hendrix | Rock | 2700000 | 70000000 |
| 2 | Miles Davis | Jazz | 1500000 | 48000000 |
| 3 | SIA | Pop | 2000000 | 74000000 |
Variabel df adalah Pandas DataFrame:
Selection#
Kita bisa memilih data suatu kolom menggunakan labelnya:
df["Artist"]
0 Billie Holiday
1 Jimi Hendrix
2 Miles Davis
3 SIA
Name: Artist, dtype: object

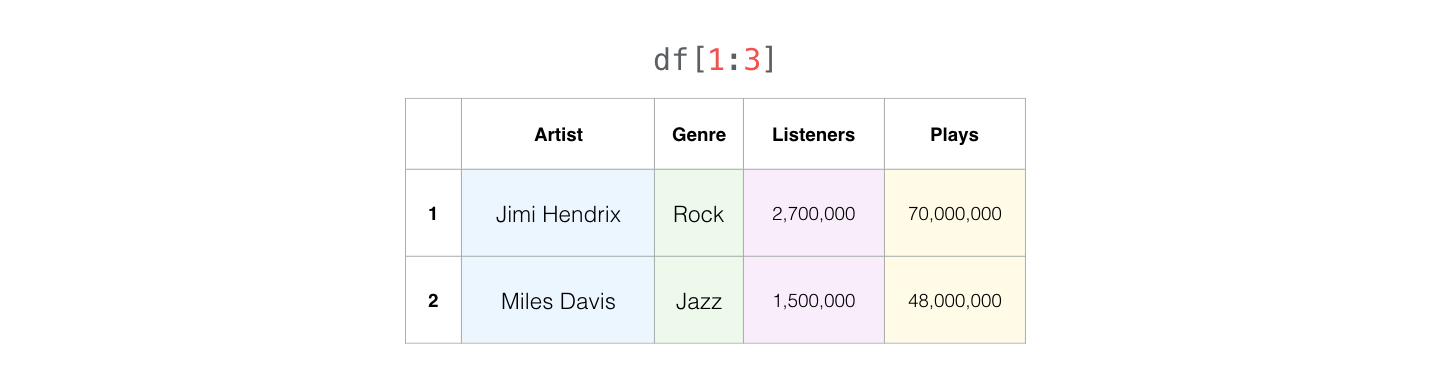
Kita juga bisa memilih baris menggunakan nomor barisnya:
df[1:3]
| Artist | Genre | Listeners | Plays | |
|---|---|---|---|---|
| 1 | Jimi Hendrix | Rock | 2700000 | 70000000 |
| 2 | Miles Davis | Jazz | 1500000 | 48000000 |
Kita juga bisa men-slice table menggunakan nomor baris dan kolom menggunakan method loc()
df.loc[1:3, ["Artist"]]
| Artist | |
|---|---|
| 1 | Jimi Hendrix |
| 2 | Miles Davis |
| 3 | SIA |

Filtering#
Ini semakin seru atau perasaan saya saja? - Desta
Dengan Pandas, kita bisa dengan mudah mem-filter baris. Misalnya:
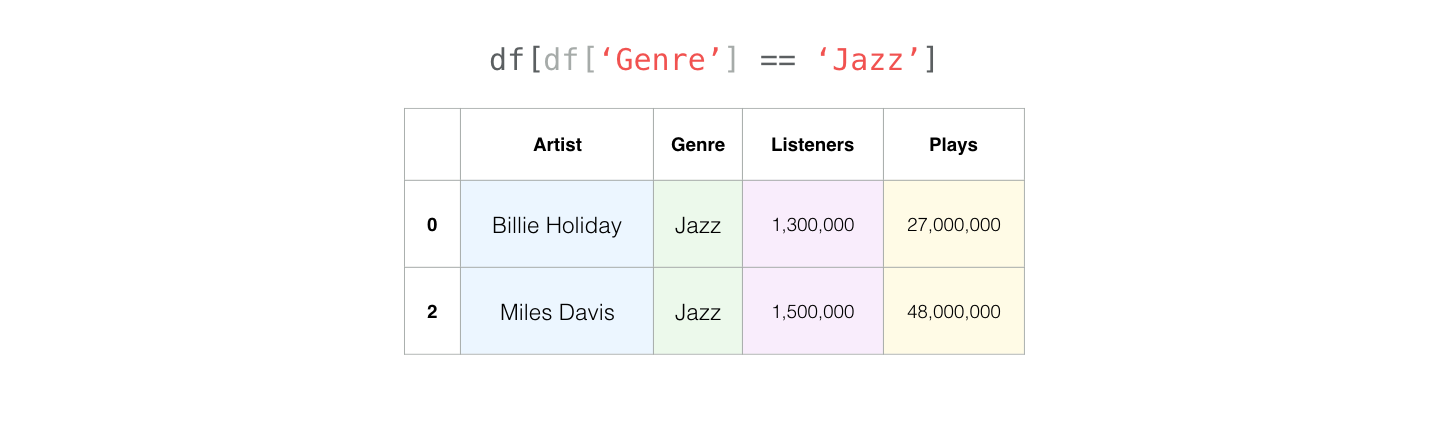
df[df["Genre"] == "Jazz"]
| Artist | Genre | Listeners | Plays | |
|---|---|---|---|---|
| 0 | Billie Holiday | Jazz | 1300000 | 27000000 |
| 2 | Miles Davis | Jazz | 1500000 | 48000000 |
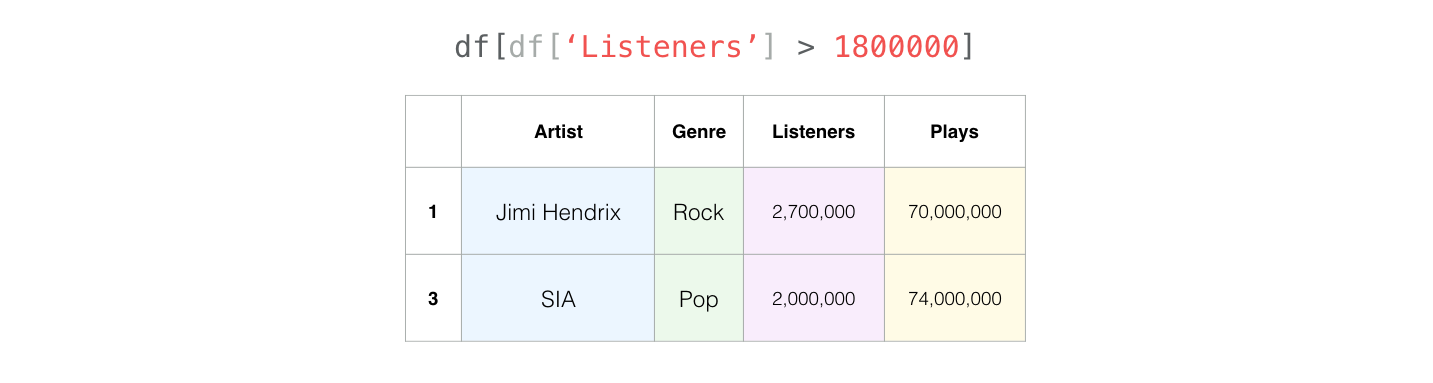
df[df["Listeners"] > 1800000]
| Artist | Genre | Listeners | Plays | |
|---|---|---|---|---|
| 1 | Jimi Hendrix | Rock | 2700000 | 70000000 |
| 3 | SIA | Pop | 2000000 | 74000000 |
Dealing with Missing Values#
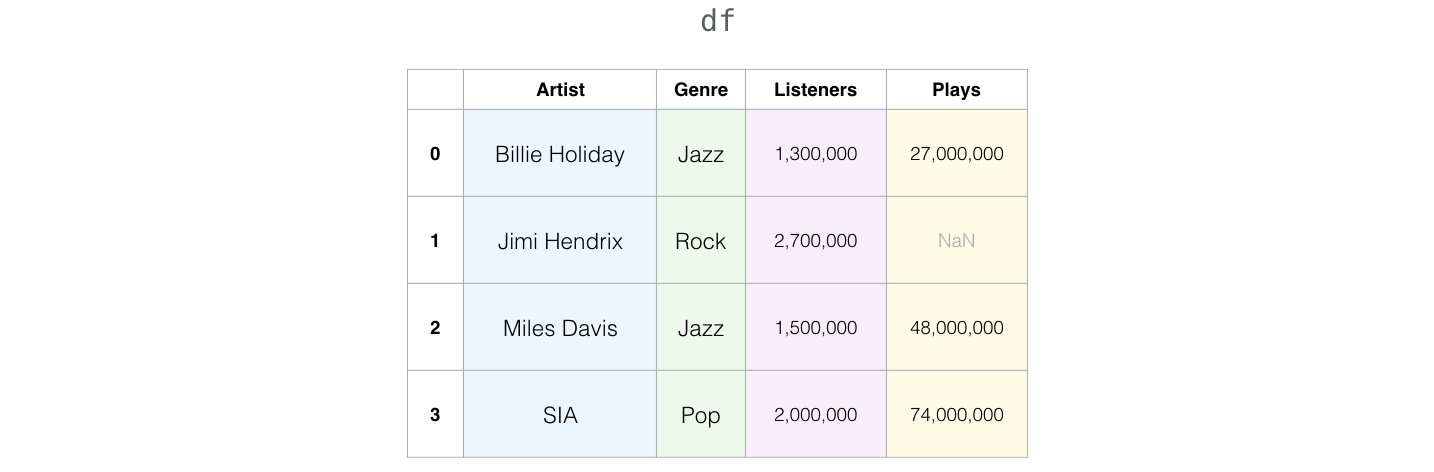
Sering kali dataset yang kamu proses pada proyek data science atau machine learning akan memiliki data yang tidak lengkap. Misalnya seperti ini:
df = pd.read_csv("../../data/music_with_na.csv")
df
| Artist | Genre | Listeners | Plays | |
|---|---|---|---|---|
| 0 | Billie Holiday | Jazz | 1300000 | 27000000.0 |
| 1 | Jimi Hendrix | Rock | 2700000 | NaN |
| 2 | Miles Davis | Jazz | 1500000 | 48000000.0 |
| 3 | SIA | Pop | 2000000 | 74000000.0 |
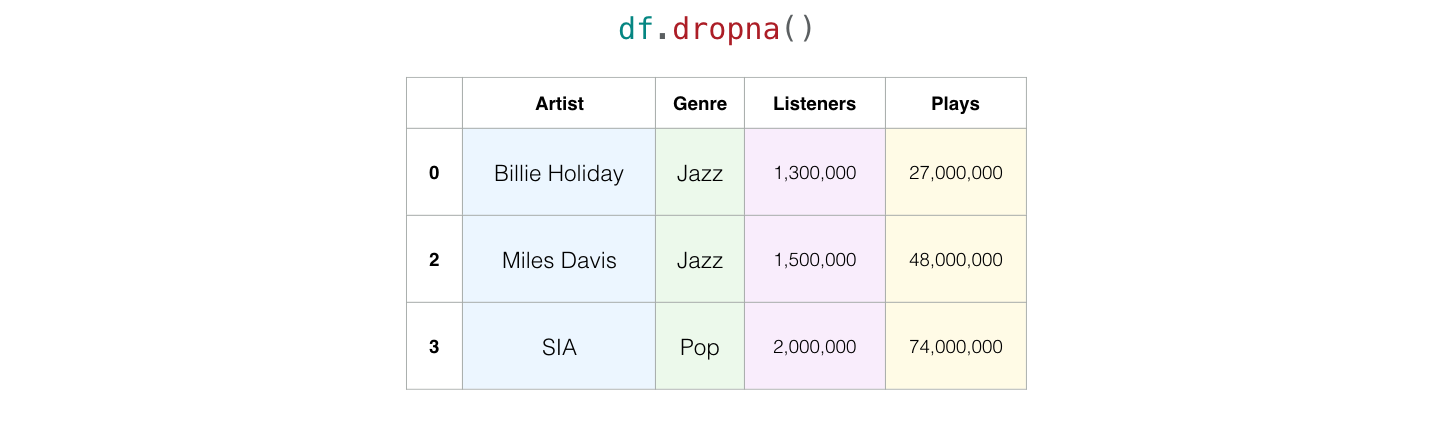
Pandas memiliki beberapa cara untuk mengatasi hal ini, salah satunya dengan menggunakan dropna() dimana kita akan menghapus baris yang datanya tidak lengkap:
df.dropna()
| Artist | Genre | Listeners | Plays | |
|---|---|---|---|---|
| 0 | Billie Holiday | Jazz | 1300000 | 27000000.0 |
| 2 | Miles Davis | Jazz | 1500000 | 48000000.0 |
| 3 | SIA | Pop | 2000000 | 74000000.0 |
Atau, kita juga bisa menggunakan fillna() dimana nilai yang tidak ada akan digantikan dengan 0.
df.fillna(0)
| Artist | Genre | Listeners | Plays | |
|---|---|---|---|---|
| 0 | Billie Holiday | Jazz | 1300000 | 27000000.0 |
| 1 | Jimi Hendrix | Rock | 2700000 | 0.0 |
| 2 | Miles Davis | Jazz | 1500000 | 48000000.0 |
| 3 | SIA | Pop | 2000000 | 74000000.0 |
Grouping#
Kita juga bisa melakukan pengelompokan dan agregasi pada data kita menggunakan Pandas.
df = pd.read_csv("../../data/music.csv")
df.groupby("Genre").sum()
| Artist | Listeners | Plays | |
|---|---|---|---|
| Genre | |||
| Jazz | Billie HolidayMiles Davis | 2800000 | 75000000 |
| Pop | SIA | 2000000 | 74000000 |
| Rock | Jimi Hendrix | 2700000 | 70000000 |
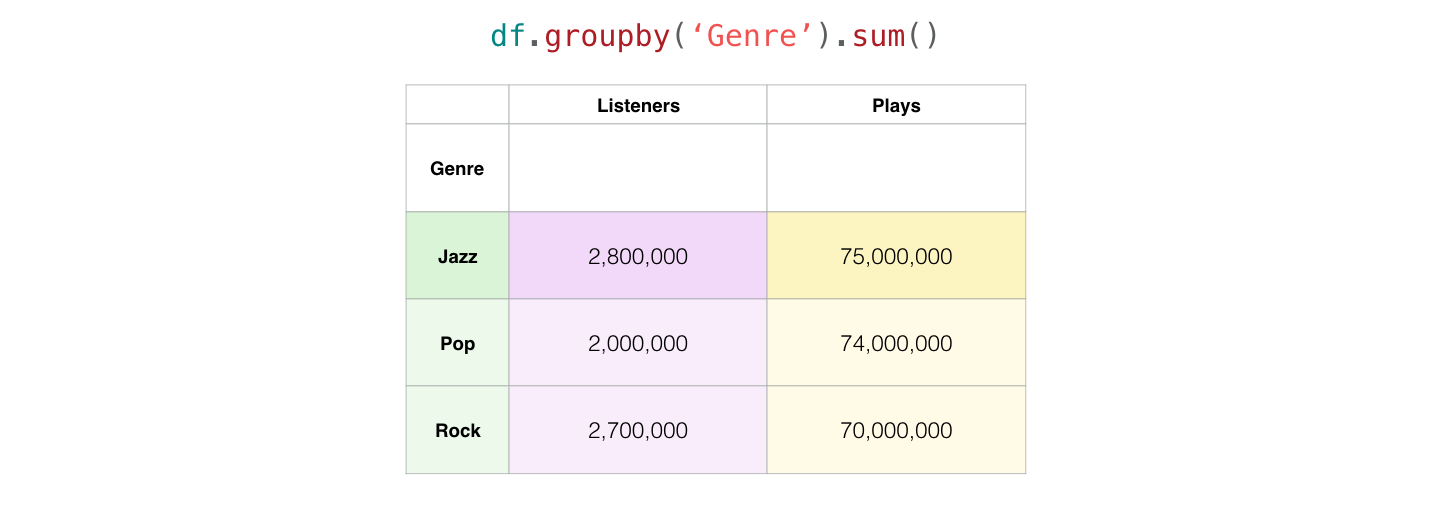
Pandas mengelompokkan dua artis “Jazz” menjadi satu baris, dan karena kita menggunakan sum() untuk agregasi, Pandas menjumlahkan total listeneres dan plays untuk dua artis Jass tersebut.
Fitur-fitur ini akan sangat berguna untuk data analisis. Grouping memungkinkan kita untuk mengelompokkan data dan menemukan insight, dan agregasi adalah pilar pertama dan fundamental untuk statistika.
Selain sum(), Pandas juga memiliki method agregasi lain seperti mean(), min(), max(), dan lainnya.
Untuk mempelejari lebih dalam tentang groupby(), kamu bisa membacanya di Group By User Guide.
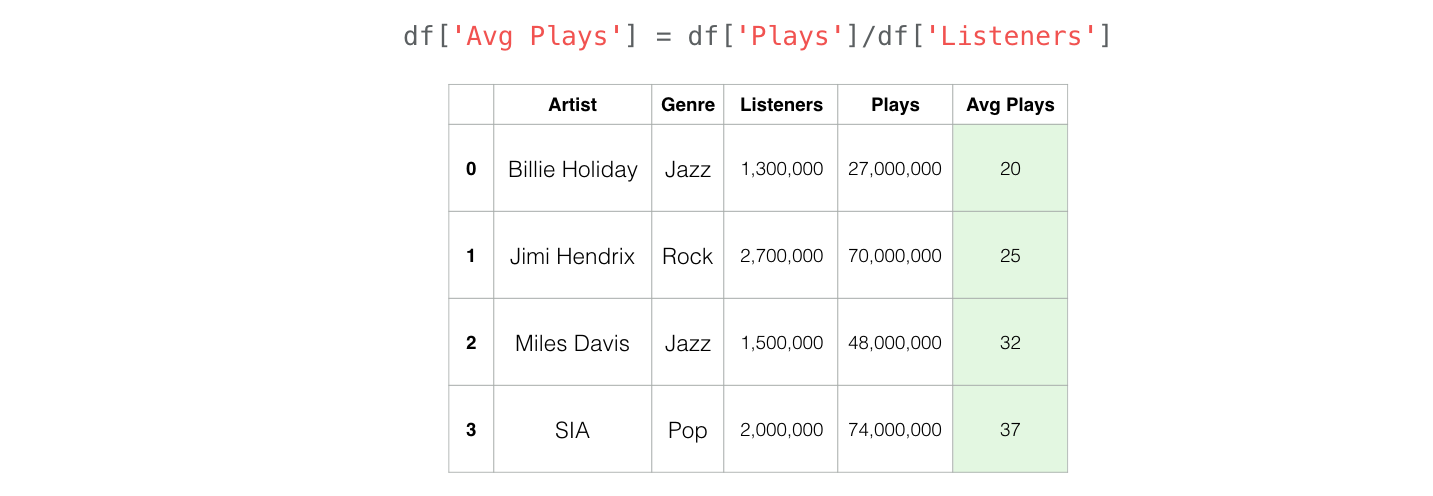
Creating New Columns from Existing Columns#
Sering kali dalam proses analisa data, kita diharuskan untuk membuat kolum baru.
df["Avg Plays"] = df["Plays"] / df["Listeners"]
df
| Artist | Genre | Listeners | Plays | Avg Plays | |
|---|---|---|---|---|---|
| 0 | Billie Holiday | Jazz | 1300000 | 27000000 | 20.769231 |
| 1 | Jimi Hendrix | Rock | 2700000 | 70000000 | 25.925926 |
| 2 | Miles Davis | Jazz | 1500000 | 48000000 | 32.000000 |
| 3 | SIA | Pop | 2000000 | 74000000 | 37.000000 |